Particle rendering revisited
22 Sep 2007Recently I was doing particle rendering for different platforms (D3D9, PS3, XBox360), and I wanted to share my experience. The method I came with (which is more or less the same for all 3 platforms) is nothing new or complex - in fact, I know people were and are doing it already - but nevertheless I’ve never seen it described anywhere, so it might help somebody.
The prerequisites are that we want a pretty flexible simulation (such as, all parameters are controlled by splines, and splines come from some particle editor – perhaps also there is some collision detection, or instead particles are driven by some complex physics only) – which means that (a) we don’t have a simple function position(time) (and likewise for other particle parameters), and (b) we don’t want to implement a fully GPU-based solution, with rendering to vertex buffer/streamout. After all, next-gen GPUs are not that powerful, we don’t have that many particles, and we often do not use all available cores (in case of PS3/360 at least) efficiently.
Also let’s suppose for the sake of simplicity that our particles are actually billboards that can only rotate around view Z axis – i.e. they are always camera-facing. This does not really matter so much, but it will make things easier.
What we’d like to do ideally is to upload particles to a buffer, and have GPU render from it. To keep the amount of data low, we’d like to copy exactly one instance of each particle, without duplication. The classical (trivial) approach is to fill VB with particle data, 4 vertices per each particle, while doing all computations on CPU – that is, vertex shader only transforms particle in clip space. This is of course not very wise (after all, we’re trying to save some CPU clocks here), so another classical (slightly less trivial) approach is to fill VB with particle data, 4 vertices per each particle, where those 4 vertices differ only in their UV coordinates. UVs act like corner identifications – you know UV coordinate in vertex shader, and you know the corner of the particle you’re processing ((0, 0) = upper left corner, etc.). Thus you can easily perform actual coordinate position calculation in vertex shader like this:
float3 corner_position = particle_position + camera_axis_x * (uv.x – 0.5) * size + camera_axis_y * (uv.y – 0.5) * size;
Also we have point sprites that seem to achieve the same thing we need – you upload exactly 1 vertex per each particle. However, they have lots of disadvantages – point size is limited, you can’t rotate them, etc.
The method I am talking about goes slightly further. Let’s divide our particle data in two parts, actual particle data (position, color, angle of rotation, etc.) and UV coordinates. Now we notice, that what we really want is to have two streams of data, one stream contains particle data without duplication, the other stream contains ONLY UV coordinates – moreover, this buffer consists of the same data, repeated many times – you have 4 vertices (0, 0), (1, 0), (1, 1), (0, 1) for the first particle, 4 vertices (0, 0), (1, 0), (1, 1), (0, 1) for the second one, etc. – so we’d like to be able to specify it once and have GPU “loop” over them.
In effect, we want something like this:
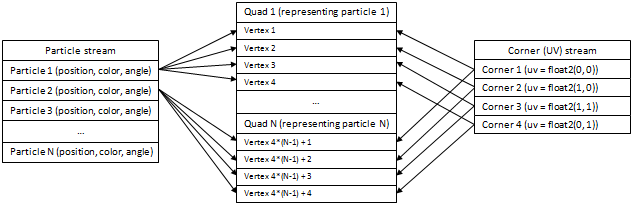
Fortunately, there is a solution that can solve it – it’s hardware instancing. Unfortunately, it’s not available everywhere – you (usually) need SM3.0 support for it. We’re going to accept this disadvantage however.
Thus we have a static stream with 4 “vertices” representing corner data (each “vertex” consists of a single float2), and a dynamic stream with N “instances” representing particles (each “instance” consists of, in our example, a position, color and angle). We render N quads, so the vertex shader gets executed 4*N times – every time we have 1 piece of instance data, and 1 piece of corner data. We compute actual particle corner position as shown above, and output it.
Note that it looks like point sprites. It has a disadvantage in that we have 4 vertex shader runs per each particle, instead of 1 with point sprites – but I have yet to see vertex processing becoming a limiting factor for particles. Also it has a more limited hardware scope. What we get in return is much more flexibility (you are not even limited to screen-facing particles; you can pass orientation (i.e. a quaternion) instead of a single angle). The amount of data that has to be uploaded by the application per frame is the same.
Now let’s go over platform-specific implementation details.
Direct3D 9
Unfortunately, D3D9 does not have “quad” primitive type, so we’ll have to use a dummy index buffer. The setup is as follows:
-
For all particle systems, create a single index buffer with 6 indices describing a quad (0, 1, 2, 2, 1, 3), and a single corner stream that will contain corner values. I chose to store UV coordinates in D3DCOLOR, though FLOAT2 is ok too.
-
Create a proper vertex declaration, that says that corner (UV) data goes in stream 0, and particle data goes in stream 1.
-
For each particle system, create a dynamic vertex buffer (note: it’s usually better to create 2 buffers and to use buffer 0 on first frame, buffer 1 on second frame, buffer 0 on third frame, etc. – thus making synchronization costs lower and lowering chance for buffer renaming), which will hold particle data.
-
Every frame, lock your buffer, upload particle data in it as is (i.e. 1 copy of data per particle).
-
Draw as follows:
device->SetStreamSource(0, shared_buffer_with_corner_data, 0, sizeof(CornerVertex));
device->SetStreamSourceFreq(0, D3DSTREAMSOURCE_INDEXEDDATA | particle_count);
device->SetStreamSource(1, buffer_with_particle_data, 0, sizeof(ParticleData));
device->SetStreamSourceFreq(1, D3DSTREAMSOURCE_INSTANCEDATA | 1);
device->DrawIndexedPrimitive(D3DPT_TRIANGLELIST, 0, 0, 4, 0, 2);
Note that:
-
You have to set corner data as stream 0 due to D3D9 restrictions
-
You pass parameters to DIP as if you want to render a single quad
In theory, this method uses hardware instancing, and hardware instancing is supported only for SM3.0-compliant cards. However, in practice, all SM2.0-capable ATi cards support hardware instancing – it’s just that Direct3D9 does not let you use it. ATi engineers made a hack that lets you enable instancing for their cards – just do this once at application startup:
if (SUCCEEDED(d3d->CheckDeviceFormat(D3DADAPTER_DEFAULT, D3DDEVTYPE_HAL, D3DFMT_X8R8G8B8, 0, D3DRTYPE_SURFACE, (D3DFORMAT)MAKEFOURCC('I','N','S','T'))))
{
// Enable instancing
device->SetRenderState(D3DRS_POINTSIZE, MAKEFOURCC('I','N','S','T'));
}
I love ATi D3D9 hacks, they are ingenious.
XBox 360
You can perform rendering with the proposed method as is – the only difference is that you’ll have to fetch vertex data manually in vertex shader via vfetch command because there is no explicit instancing support. For further reference, look at CustomVFetch sample.
PS3
You can perform rendering with the proposed method as is – you’ll have to set frequency divider operation to MODULO with frequency = 4 for corner stream, and to DIVIDE with frequency = 4 for particle data stream.
Direct3D 10
I have not actually implemented this for Direct3D 10, but it should be pretty straightforward – you’ll have to create proper input layout (with D3D10_INPUT_PER_INSTANCE_DATA set for all elements except corner data), create index buffer with 6 indices as for D3D9, and then render via DrawIndexedInstanced(6, particle_count, 0, 0, 0);
Note that for Direct3D 10 you can also render from your particle data stream with D3D10_PRIMITIVE_TOPOLOGY_POINTLIST, and perform quad expansion with geometry shader. This in theory should somewhat speed up vertex processing part, but in practice I have very bad experience with geometry shaders on NVidia cards performance-wise. If you have an ATi R600 or (perhaps) next-generation NVidia card, I’d be happy to hear that things are okay there.
| Robust unit cube clipping for shadow mapping » |