Quantizing floats
14 Dec 2010Over the next few posts I’d like to write about optimizing mesh data for run-time performance (i.e. producing vertex/index buffers that accurately represent the source model and are as fast to render for GPU as possible).
There are several important things you have to do in order to optimize your meshes, and one of them is packing your vertex/index data. Packing index data is trivial - for any sane mesh there are no more than 65536 unique vertices, so a 16-bit index buffer is enough; this is a small thing, but trivial to do. Reducing the vertex size is more complex.
In order to compress your vertex data you have to know the nature of your data (sign, range, special properties (like, is it a normalized vector), value distribution) and the available compression options. This is the topic for the next article; today I want to talk about quantization.
All methods of vertex compression that are trivially implementable on GPU involve taking the floating-point source data and storing it in a value with less bits of precision; usually the value is either an integer or a fixed-point with a limited range (typically [-1; 1] or [0; 1]). This process is known as quantization.
The goal of quantization is to preserve the original value with as much accuracy as possible - i.e., given a decode(x) function, which converts from fixed-point to floating-point, produce an encode(x) function such that the error, i.e. abs(decode(encode(x)) - x), is minimized. Additionally it may be necessary to perfectly encode a finite set of numbers (i.e so that the error is zero) - for example, it is usually useful to preserve endpoints, i.e. if you’re quantizing pixel component values, you’re encouraged to encode 0 and 1 perfectly, or pixels that were previously fully transparent will start to slightly leak some color on the background, and pixels that were previously completely white will give a dark color if you exponentiate their intensity.
Note that the error function is defined in terms of both encode and decode functions - the search for quantization function should start with the decode function. For GPU, decode functions are usually fixed - there are special ‘normalized’ formats, that, when used in a vertex declaration, automatically decode the value from small precision integer to a limited-range floating point value. While it is certainly possible to use integer formats and do the decoding yourself, the default decode functions are usually sane.
So, what are the functions? For DirectX 10, there are *_UNORM and *_SNORM formats. Their decoding is described in the documentation: for *_UNORM formats of n-bit length, the decode function is decode(x) = x / (2^n - 1), for *_SNORM formats of n-bit length the decode function is decode(x) = clamp(x / (2^(n-1) - 1), -1, 1). In the first case x is assumed to be an unsigned integer in [0..2n-1] interval, in the second case it’s a signed integer in [-2n-1..2n-1-1] interval.
In for the UNORM case the [0..1] interval is divided in 2^n - 1 equal parts. You can see that 0.0 and 1.0 are represented exactly; 0.5, on the other hand, is not. The SNORM case is slightly more complex - the integer range is not symmetric, so two values map to -1.0 (-2n-1 and -2n-1 - 1).
This is only one example; other APIs may specify different behaviors. For example, OpenGL 2.0 specification has the same decoding function for unsigned numbers, but a different one for signed: decode(x) = (2x + 1) / (2^n - 1). This has slightly better precision (all numbers encode distinct values), but can’t represent 0 exactly. AMD GPU documentation describes a VAP_PSC_SGN_NORM_CNTL register, which may be used to set the normalization behavior to that of either OpenGL, Direct3D 10 or a similar method to Direct3D 10, but without [-1..1] range clamping (i.e. the actual range is not symmetrical).
Once we know the decoding formula, it’s easy to infer the encoding formula which gives the minimum error on average. Let’s start with unsigned numbers first. We have a [0..1] floating point number, and a 3-bit unsigned integer ([0..7] integer range).
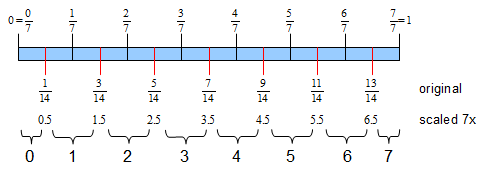
First let’s mark all values that are exactly representable using the decode function on the 0..1 range (the top row of numbers, and black lines denote these) - just decode all integers from the range and draw a line. Now, in order to minimize the error, for every number we have to encode we have to pick the closest line, and select the corresponding number. I’ve drawn red lines that are exactly in the middle of corresponding black lines; all numbers between two red lines (which correspond to values in the row labeled ‘original’) will be encoded to the same number. The number each subrange should encode to is specified in the bottommost row.
Now we can visualize the encoding; all that’s left is to provide a function. Note that the encoding is not exactly uniform - the size of leftmost and rightmost subranges is half that of all other subranges. This is not a problem, since we’re optimizing for the minimal error, not for the equal range length.
The function is easy - if you multiply all numbers from the row ‘original’ by 7 (2n - 1), you’ll see that all that’s left is to apply the round-to-nearest function; since we’re limited to unsigned numbers, the encode function is encode(x) = int (x / 7.0 + 0.5) (which is a standard way to turn round-to-zero, which is the C float-to-int cast behavior, to round-to-nearest for positive numbers).
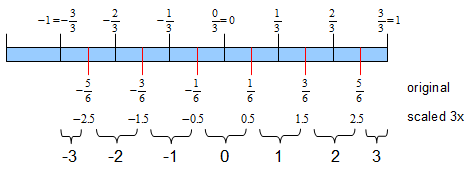
Here is another image for the signed numbers, using Direct3D 10 rules. The range is [-1..1], we still have a 3-bit integer with [-4..3] range - we’re going to provide an encoding function that gives us the number in [-3..3] range. Using exactly the same reasoning as above, to encode the number we have to multiply it by 3, and then round to the nearest integer. Be careful - since float-to-int cast does a round-to-zero, or a truncate, the round function is slightly more complex. The encode function is as follows: encode(x) = int (x / 3.0 + (x > 0 ? 0.5 : -0.5)).
Just for reference, three functions for quantizing values to 8 bits are:
// Unsigned quantization: input: [0..1] float; output: [0..255] integer
encode(x) = int (x * 255.0 + 0.5)
// Signed quantization for D3D10 rules: input: [-1..1] float; output: [-127..127] integer
encode(x) = int (x * 127.0 + (x > 0 ? 0.5 : -0.5))
// Signed quantization for OpenGL rules: input: [-1..1] float; output: [-128..127] integer
encode(x) = int (x * 127.5 + (x >= 0 ? 0.0 : -1.0))
3/4/2014: the original version of signed quantization for OpenGL was incorrect for negative values; the bug is fixed. See comments for discussion.
These functions are the perfect foundation for the next step: reducing the size of vertex buffer by reducing the vertex size. Until next time!
| « Exit code trivia | A queue of page faults » |