Year of independence
31 Dec 2024I am happy to report that life after Roblox does indeed exist.
When I quit, people told me I should take some time off, relax, unwind, recharge, travel… That would make sense1! What I did instead however is a combination of “writing a lot of code” and “talking to a lot of people”. Many dozens of companies and individuals reached out - thank you to everyone who did! - and I had a lot of fun meetings and conversations and got a better sense of what people are building these days and why.
A lot of the discussion was around the technology in the spaces that I am broadly familiar with - game development, simulation, low level systems engineering. In some ways, it was too comfortable, as in many cases I could see exactly what the years ahead for that company would be like - which was exactly what I was not looking for.
At the same time, I was also fascinated by the technology behind LLMs. The claims about achieving AGI seem wildly exaggerated2, but the tech is still useful and bewildering. To try to get a better sense of what this is all about and how all of that works, I ended up reading more papers in the first few months of my “funemployment” than I’ve read in the previous decade, and started a new open source project, calm, which is a from-scratch single-user LLM inference engine for CUDA & Metal (and CPU SIMD I guess because why not).
This project was born out of my desire to learn more but also out of dissatisfaction with the state of the art at the time. To run the models you could use slow and bulky PyTorch with endless environment setup issues and never ending issues around quantization support3, or, even worse, try to use NVidia’s TensorRT-LLM which is impossible to build without Docker containers and dreadful to build with them; compared to that, llama.cpp was a breath of fresh air - but it still felt too bulky and inefficient compared to what seemed possible. Starting a new project in an unfamiliar field is daunting because you need to go from “nothing works” to “something works” before considering efficient implementations - fortunately, Andrej Karpathy’s llama2.c appeared just in time, so I copied the code and started hacking, ultimately ending up rewriting a 1000-line .c file into a 4000-line project that is a very very very fast single-user LLM inference engine.

Before this project, I’ve spent almost two decades programming GPUs, but somehow have never done it in CUDA. I had a rough understanding of what that entails of course, but it was still a lot of fun discovering the peculiarities of the modern NVidia hardware, working with excellent NVidia performance tools, and coming up with ideas for how to structure the data and kernels to squeeze as close to the theoretically possible performance as possible. I even ended up going into some wild corners of multi-GPU programming and wrote a fully fused cooperative kernel (NVidia, please don’t deprecate these) that managed to run on H100 with okay efficiency4.
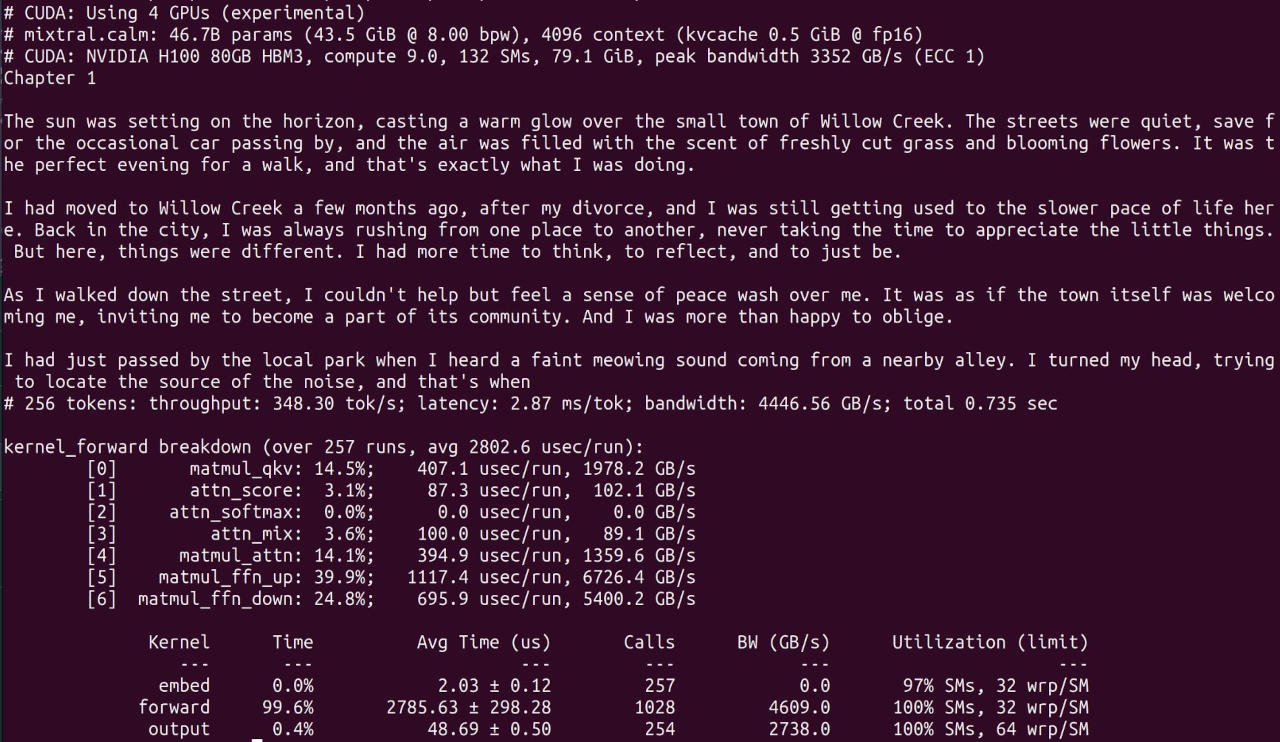
I also ended up writing a Metal version, just to see what Apple hardware is really like to work with. In regular graphics programming, people tend to look at Metal vs Vulkan and Metal is so much easier to work with and makes so many reasonable choices - although not everything is great in Metal - but trying to port CUDA to Metal was exactly the opposite. Things worked but were much clunkier, requiring manual resource management and dispatch; lack of robust scheduling guarantees necessitated inefficient dispatch flow and restricted optimization options; profiling tools were mostly not very useful; writing your own profiling tools was mostly not an option5; and I ended up having to use Dougall Johnson’s applegpu project to disassemble some of the kernels to be able to optimize them better. Overall it was “fine” but not entirely enjoyable; the kernels do not scale as well to higher-end Apple models like M3 Max, but since I never had direct access to these - another big issue for the Apple ecosystem is the almost non-existent cloud infrastructure, whereas with NVidia you can rent any GPU in a few minutes and get direct SSH access for a few $ an hour! - I mostly left it as is.
At the end of this journey, I got to the point where getting even more performance (on NVidia HW) would really require rethinking the entire pipeline - not just using an off-the-shelf model, but at the minimum doing distillation into differently structured models, which requires access to a lot of data that was difficult to get and a lot of compute resources, far beyond “sure let’s spend $100 to play with H100 on a weekend”. This was no longer feasible as an individual - and after a few weeks of considering joining an AI lab, I ultimately decided the path was not mine to take.
Something I would tell everybody I’ve talked to this year is that not only do I not know what field I want to explore in the future, but I also don’t know the mode I want to explore that field in - individual contributor at a company that pursues lofty goals that ultimately require a large team? technical visionary that guides the efforts of a said large team? a blend at a small company where both can be highly impactful in combination? cofounder at a startup starting from a blank slate and hopefully reaching the stars? - but the more I talked to different teams in different fields the more I got a sense that without an idea that captivates me so much I just have to do it, which even the LLMs were not, losing the complete freedom and independence I’ve been enjoying during the first few months was just… not worth it.
I toyed with a few more ideas around LLMs but ultimately ended up shelving that entire direction. One difficult conflict to resolve here is that the entire technology stack that the ML industry has built is deeply flawed, and yet taking a real shot at fixing that requires complete dedication, significant resources, and - to get real uptake - strong support and connections across the industry. Which again would shift the balance from “independence” to “corporate” too much for comfort, in addition to other practical issues.6
Not quite certain where to go from here, I decided to spend a little more time on meshoptimizer. In terms of the actual project, I had a vague set of directions in which to take the core library as well as some glTF-related work I’ve been meaning to get to; and I was also wondering if I could make the development sustainable through some sort of hybrid sponsorship model. The former was tangible; the latter felt difficult to orchestrate. I know little about this so take it with a grain of salt, but I was skeptical of the “donation” based sponsorships ala GitHub Sponsors / Patreon (it works for a few incredibly successful projects, but seems to require endless community outreach and my baseline expectation was “funding my morning coffee would be non-trivial”), and corporate sponsorship means constantly working to find new companies, fighting legal and accounting in every new sponsor to settle the terms, justifying the value (ugh), balancing requests for features from paying sponsors with what I felt was right to do, etc. Ultimately this seemed like it would both erode the independence and create a lot of new coordination and funding work of the type that I do not enjoy to be viable.
So without a firm plan, I thought, well, I should just focus on meshoptimizer for a little bit and see what happens. And then I discovered something I used to know but have since forgotten:
Graphics is fun, actually.

As exhilarating as exploring the field of multiplying giant matrices quickly to steer the weights to be able to perfectly model content of questionable copyright status was, it turned out that working with 3D art7 and rendering techniques, hacking on meshoptimizer and writing shaders was… fun.
gltfpack, which is co-developed alongside meshoptimizer library, was fun to hack on because it meant working with complex scenes - meshes, scene graphs, animations, textures, oh my! - and while it is lighter on the complex algorithms, improvements are fulfilling because they support an ever-expanding glTF ecosystem and help people ship their content or make it more efficient.
meshoptimizer proper was fun to hack on because it required delving deep into undocumented hardware details, learning about established algorithms and inventing new ones, and making the library more useful which helps many companies that use it - if your project is not on this list, please let me know! There’s a large amount of untapped potential in interesting and useful algorithms that can be hidden behind a small API surface - in contrast with something like pugixml where a lot of the value is in the API surface itself - and improving the library internals helps many different engines that use it with minimal integration or adaptation effort.
Importantly, the pace and direction of development are unconstrained - while fundamentally my goal is to make both projects useful, if a processing algorithm could be a little faster and I feel like I want to spend some time on this, that’s what I’m going to spend time on8; if mesh shading efficiency can be improved then I can do this even if many existing production pipelines are still stuck with index buffers and vertex shaders; if improving an algorithm requires research in an unconventional direction then that’s what is on the table; and if a particular week is just not a good week for working then I guess code is not being written.
That said, in addition to the perpetual lack of funding, one challenge with open source (at least in fields I’m used to like game development) is the limited feedback and contributions you get from the companies that use the technology. Contributions in open-source are a separate nuanced topic which maybe I will write about one day, but limited feedback coupled with working on the library in isolation means that there are aspects of the library that don’t work as well as they could which you don’t know about and there’s portions of the library that simply don’t exist because this is not a problem you are aware of - these issues sometimes just remain unsolved, and sometimes gain proprietary solutions that companies keep re-inventing independently.
To try to work around this problem a little bit, I’ve also spent some time contributing code to Godot Engine (123456789) and Bevy Engine (1234). Working with Godot helped me develop some algorithms further and significantly improve the mesh import pipeline processing using other algorithms, which prompted improvements in meshoptimizer documentation among other work; working with Bevy helped me understand the requirements of hierarchical clusterization (with some improvements that have been made to support this use case better, although this journey is far from over and hopefully more things will happen in the future) and work a little more with Rust (which was fun but do not expect a rewrite-in-Rust or new Rust projects from me in 2025).
Something that I completely forgot about when writing this is that I also spent some time working on Luau! It’s nothing ground-breaking or earth-shattering, but I’ve contributed quite a few (1234567890) codegen and compiler optimizations including significantly improved vector operation lowering and a few other improvements here and there, and I am hopeful that Luau will get a pretty good lerp function soon™
And then I got a reach-out from someone working at Valve with an offer to sponsor meshoptimizer development.
While I knew that Valve uses meshoptimizer in various games through third-party license notices (thank you! not all companies that use meshoptimizer do attribution - sometimes this is forgotten, sometimes it’s technically-okay-but-I-wish-you-still-did-this because it’s part of the content pipeline that is never shipped to users), I did not realize how many components are used. Working through the details with the team made me hopeful that this can be a case of “aligned” sponsorship or open source funding done right. I had a rough roadmap for meshoptimizer development, and it turned out that that roadmap is broadly interesting to Valve as well, so no pivot was involved; so far there is minimal extra burden as well. Neither I nor meshoptimizer are affiliated with Valve in any way, and it is still the case that the development direction and priorities are determined entirely by me (driven by the needs of different users!). Besides just funding, more direct communication helps improve the library further, by testing on production-quality data and gaining more insight into what works, what doesn’t, and what could be possible.
There is a little bit of a risk of a bus factor here: having just one sponsor means the risk of losing it is that much higher - either the company could lose interest or the dynamics could change such that I would see my own, or my project’s, independence unraveling - something that as you can probably tell is more and more important to me. But so far I’ve been very pleasantly surprised and there is no sight of a bus coming so for now, my plans graduated from “focus on meshoptimizer for a little bit” to “focus on meshoptimizer for a while”.
Notably, gltfpack is still being developed in spare time. If your company is interested in funding gltfpack development with no strings attached, feel free to reach out by e-mail!
As a result of all of this, meshoptimizer has seen significant work done this year, and I expect this to continue. While this is an imperfect metric, here’s a pie chart that aggregates, for each line of the core library, the year this line changed last. meshoptimizer does not go through mass spontaneous refactors and the code is generally changed when it needs to improve, so I like this as a rough way to gauge the progress as well as the robustness of some parts of the codebase.
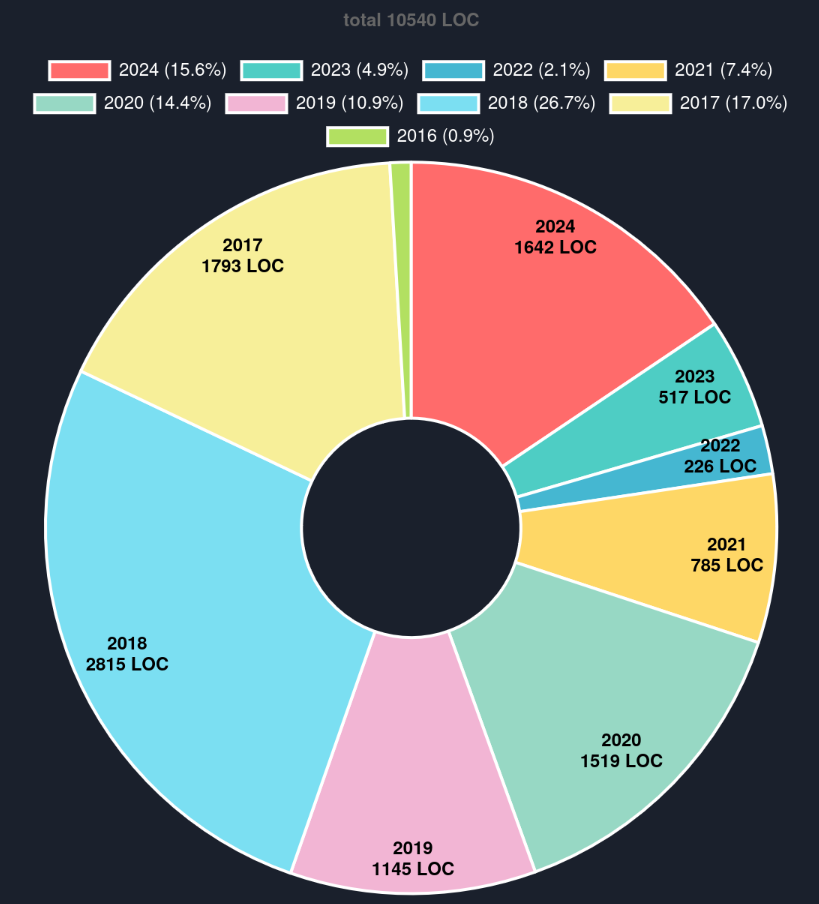
In terms of large features, simplification has seen a lot of work this year (sparsity and explicit locks for hierarchical LODs, much better attribute-aware simplification, many improvements to topology handling and error metrics, component pruning), meshlet clustering has improved a little further (more to come in 2025), meshlets can be optimized for locality to help with rasterization efficiency on NVidia, meshoptimizer now supports provoking vertex index buffer generation based on John Hable’s work published on SIGGRAPH 2024, and I’m wrapping up improvements to the vertex codec (smaller meshes, even faster decoding, and variable encoding speeds!) as we speak. gltfpack has seen many small improvements as well as better welding for models with unnecessary normal splits, automatic geometry deduplication which reduces output size on some large scenes, as well as texture compression improvements.
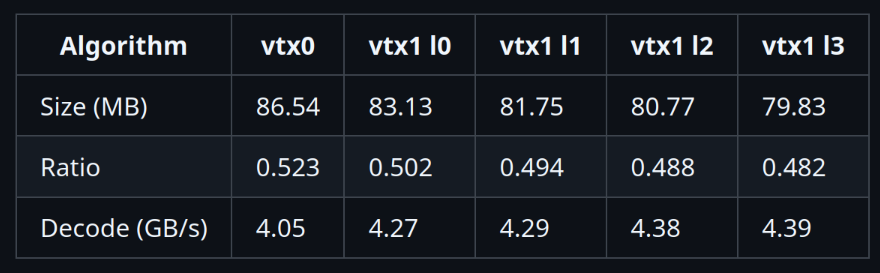
Working on meshoptimizer and gltfpack is fun and rewarding, but is not relaxing: both are production projects that are widely used and have many diverse demands. You can’t simply write a few lines of code and commit them. Both have issue reports of… varying… quality… that need to be looked at, and in general working on them still feels like… work. This is something that made me go back to the early part of the year and think about calm - the name stands for “CUDA Accelerated Language Model inference”, but also for a different development paradigm, as the first thing I’ve done when I created the project was to write “the goal of this project is experimentation and prototyping; it does not aim to be production ready or stable” in the README and blanket disable GitHub Issue reports. Because this project was fundamentally for me to tinker with, and if it doesn’t work for anyone else, it’s their problem, not mine.
In part because of this, but also to keep up with the ever-changing ecosystem and keep a fresh perspective on real-time graphics despite not working in that field directly anymore, I also “rebooted” my Vulkan renderer project, niagara.
This project was started in 2018 (wow, time flies!) as an educational YouTube stream series - the goal was to write a simple but modern Vulkan renderer from scratch, on stream, both to have a useful resource for people who are learning graphics programming and as a way for me to experiment with video streaming which I have not done before that. The project ran in an active mode during 2018, and then mostly went on hiatus, as I felt like it reached a good baseline for pure geometry rendering (featuring meshlet-based renderer, GPU culling, object occlusion culling, etc.) and significant further progress would require a lot of new concepts. I’ve done a couple of streams in 2023 after getting a new AMD GPU, as the AMD mesh shading pipeline was different from the hardware perspective and required more work to get it up to the level of performance I considered acceptable, but did not have further plans.
However, there were still many interesting areas of graphics that project - and I personally - left unexplored; I was particularly interested in topics new to me, as a byproduct of working at Roblox for the last decade+ my working level of rendering stopped around “late PS3-early PS4” level, notably excluding ray tracing, bindless, the exciting world of temporal jitter and “boiling soup of pixels” and other revolutionary advances since. So a few months ago I decided that this project can serve two goals at once: continue being an educational resource for people who want to learn graphics, and also serve as a playground “I can just write code and nobody can stop me” for myself.

As part of this, I now sometimes write code for this project off-stream but also still write code on-stream for topics that feel fun to explore with a live audience. The project now loads glTF scenes, uses bindless texturing, deferred shading, HW raytracing9 with soft(ish) shadows, with many other things planned for the future, time permitting :) If you have not seen the project before and have a spare week or two, the full YouTube playlist is just 82 hours for now!10
So, where does this leave us, a few short hours before 2025 begins? What are the plans and resolutions? Where will I be and what will I do in 12 months? Excitingly, the answer remains the same - I don’t know! But I think more and more I appreciate the incredible power that freedom and independence give you, and it becomes less and less likely that you will see an “I am joining a company” announcement from me in the future. “I am starting a company” is still on the table for now ;)
And maybe most importantly: by combining “work can be fun” and “you can just do things”, we arrive at “you can just do work that is fun”. Hopefully for many years to come.
-
And some travel and unwinding did happen at various points of this year :) But this is not a travel blog… ↩
-
As recently as a few days ago I needed to write a 5-line function and both Claude and O1 failed completely at doing that for me, so I had to do it myself - in a classical xkcd automation moment, it took me much less time to do it myself than to try to get an LLM to do it for me. ↩
-
I hear it’s better these days with projects like gpt-fast and torchao; there’s also now alternatives like tinygrad that are much more pleasant to work with. ↩
-
This is entirely impractical - why would you ever optimize a single request latency to death on an 8xH100 system? - so this is on a branch that will never be merged. ↩
-
calm implements a small CUDA profiler using the CUPTI trace library, which was helpful to profile on cloud hardware, and more convenient to work with vs NVidia tools at times - but this was not strictly necessary, and the fact that you can even do this speaks to the excellent engineering discipline in the CUDA ecosystem. ↩
-
While I have some misgivings about both, I look forward to efforts of Modular and TinyCorp. ↩
-
Of perfectly certain and proper copyright status, thank you for asking. ↩
-
Content pipeline processing speed is important to me; it is also important to some meshoptimizer users who have multi-hundred-million-triangle meshes to process, but I am sure not the highest priority for others. ↩
-
I even ended up contributing a small patch to radv to use an RDNA3 feature to accelerate RT traversal, although a lot more work is required for radv to be competitive with AMD drivers in this area. ↩
-
The audio quality in the early days was pretty rough :( Maybe just watch the streams since 2023! ↩
| « Unlearning metrics and algorithms | Measuring acceleration structures » |