Quantizing tangent frames
30 Apr 2026I’ve been working on tangent space generation recently, and also pondering the tradeoffs between QTangent and normal-angle storage. So when, in a completely unrelated discussion, someone said “you could store tangent and normal as two RGB10A2 attributes”, I decided I should measure this once and for all and write it up.
This is going to be a quick post that doesn’t intend to do any original research. Instead it aggregates the research that other people have done, and examines different representations from an accuracy point of view. Some of these are common or obvious, but some are sufficiently obscure that people may not have heard of them.
So say you have a vertex and you would like to store tangent frames in it. Memory is at a premium and memory bandwidth is always valuable to conserve; what representation do you choose?
Bitangent and orthogonality
First of all, we will assume that your tangent frames are orthogonal: tangent is orthogonal to the normal, and bitangent1 is orthogonal to both of them. The former is generally true if you use MikkTSpace for tangent construction2. The latter is not generally true even if you use MikkTSpace - as it will happily generate a tangent frame with bitangent and tangent not really orthogonal to each other, and is correct to do so when the UV mapping is skewed. However, almost every production renderer in existence throws bitangents away and reconstructs them as cross(normal, tangent.xyz) * tangent.w; yours should too - this is a common convention and an extra vector is too much overhead to store.
It is common to do this reconstruction in the fragment shader: this is cheap and reduces interpolation cost. Technically, bitangent reconstruction in the fragment shader produces different results compared to doing it in the vertex shader; if you use normal map baking workflows, your baker likely allows you to choose between these; otherwise it’s unlikely to matter for rendering quality. Everything else we discuss here is presumed to run in the vertex/mesh shader.
Note that the tangent is a 4 component value: a normalized vector, and a tangent frame orientation. The orientation is always either +1 or -1, and it’s important to preserve it to be able to handle arbitrary UV orientation; even if your texture mapping is not “mirrored” in a traditional sense, you still may have areas of the mesh where the orientation is reversed.
In what follows, we will assume orthonormal3 frames: T, B and N are normalized and orthogonal to each other, forming a basis.
Baseline
Since we only have two separate vectors to store, and they are normalized, their components are between -1 and 1. Thus, you could store them separately from each other, using three components per vector and an SNORM encoding; it’s not entirely unreasonable to use 10 bits per component, and the orientation bit can land in one of the 4 spare bits. This can be our baseline.
What we can do for each encoding scheme is run it over the tangent frames of a typical mesh, encode & decode tangents and normals, and then measure the deviation between the original, 32-bit floating-point vectors, and the reconstructed versions. There are different ways to look at the error but we’ll look purely at the angular deviation, in degrees, and look at average and maximum errors for the two vectors separately; since bitangent is computed via a cross product, its error could be a little higher.
This gives us our first result (results are somewhat mesh-dependent but I will be using a not-too-remarkable mesh asset that exhibits similar error properties as other meshes in my dataset):
| codec | bits | n_avg | n_max | t_avg | t_max |
|---|---|---|---|---|---|
| snorm10x6 | 60 | 0.0310 | 0.0949 | 0.0326 | 0.0907 |
~0.03 degrees average error for both vectors is pretty decent; however, we are using 8 bytes for this. In the rest of the post, we will look at a few 4-byte encodings instead; if you have 8 bytes to spare, this encoding is not optimal since you could get a much lower error using the same 8 bytes, but you might not care - this error is usually small enough. In case you have tighter error tolerances than the rest of the post assumes, you can trivially extend the techniques listed below to use more bits; for example, you can often find a 16-bit gap somewhere else in your vertex (say, as a fourth component of quantized position), in which case you could expand many of the techniques below to 48 bits (16+32) and have dramatically smaller errors too.
Octahedron encoding
Octahedron (octahedral?) encoding gives us a way to encode each unit vector using just two components; and because we have 32 bits, we could use 8 bits per component! Well, almost, because we also need to store an orientation bit somewhere, or reduce the bit count; for now, let’s see what happens if we assume the extra bit can magically go somewhere else and use 8-bit octahedral encoding for two vectors:
| codec | bits | n_avg | n_max | t_avg | t_max |
|---|---|---|---|---|---|
| oct8x4 | 32 | 0.2849 | 0.9113 | 0.2882 | 0.9117 |
The good news is that we are using half as much space as we used to; the bad news is that our error is up to 10x higher than it used to be. This is not an apples-to-apples comparison as we’ll see in a bit, in that not only did we switch the encoding, but we also dropped the bit count from 10 bits per axis to 8 bits for each of the two octahedral channels. This can still be a reasonable option if we have more bits to spare; for example, with 48 bits you could do 12-bit octahedral encoding for each vector in theory. But this is just a stepping stone and I mention it here not because you should use it, but to introduce the concepts gradually.
As an aside, if you use octahedron encoding, you should be aware of two important variants:
- Nicer decoding function courtesy of Rune Stubbe; it is described in the post linked above, in case the Twitter link ever bursts into flames. You should always be using this decoding method if you need octahedron decoding.
- Signed octahedron encoding by John White. This method allows you to use an odd number of bits when encoding a vector; for example, here we could encode normal with octahedron encoding with 8 bits per channel, and tangent with signed-octahedron encoding with 7 bits per channel (and 1 sign bit); this would leave us 1 bit for orientation. We will come back to this.
Quaternion encoding
Because the TBN is an orthonormal basis, we can represent it in any way that a rotation matrix can be represented; in particular, quaternions are a very useful representation. Crytek published Spherical Skinning with Dual-Quaternions and QTangents that presents the method, where a quaternion is constructed from the matrix and can also optionally carry the orientation sign, if it’s flipped into a canonical form with w > 04. After decoding the quaternion, we can reconstruct the original vectors using a quaternion-to-matrix formula.
In practice T and N may not be orthogonal, so it is valuable to orthogonalize the frame first: subtract
dot(N, T) * Nfrom the tangent, renormalize it, and reconstruct the bitangent. This makes sure the normal is preserved by the quaternion encoding even though the tangent direction changes during orthogonalization.
To store all 4 quaternion components, we must make do with just 8 bits per component, with or without aforementioned orientation packing:
| codec | bits | n_avg | n_max | t_avg | t_max |
|---|---|---|---|---|---|
| quat8x4 | 32 | 0.3208 | 0.8738 | 0.3296 | 0.9022 |
This is pretty underwhelming; we are getting similar results to two-vector encoding. The quaternion we are encoding is unit-length, so it can be tempting to drop the fourth component, .w, and reconstruct it; this affords us 10 bits per component instead of 8. Unfortunately, while it slightly improves on the average error, it makes the worst case error much worse: reconstruction of any specific quaternion component has regions of instability where the input .w is small, and reconstructing it from quantized xyz results in 0 - which can rotate the basis too much.
A classical solution to this involves dropping the maximum (absolute) component and storing its index which uses an extra 2 bits. In this form we could use 10 bits per axis for the three smallest values, and adjust the quantization range as their absolute value can’t exceed sqrt(2)/2; if we hand-wave away the orientation bit which we don’t quite have space for here, we could use 10 bits per axis and a 2-bit axis index:
| codec | bits | n_avg | n_max | t_avg | t_max |
|---|---|---|---|---|---|
| quat10x3+i2 | 32 | 0.0632 | 0.2046 | 0.0640 | 0.1988 |
This is getting quite reasonable; our errors are only ~2x larger than the original 8-byte representation, and we only use 32 bits for the quaternion, plus an extra orientation bit that surely you can stash somewhere else in the vertex. Unfortunately, quaternions encoded like this are a little awkward to decode on the GPU because you need to swizzle the vector based on the axis index. We could use the Cayley transform described in the article linked above, which is much nicer algebraically and actually has a spare bit for the orientation, but it produces larger errors in this case which is not ideal:
| codec | bits | n_avg | n_max | t_avg | t_max |
|---|---|---|---|---|---|
| quat10x3-cayley | 30 | 0.1191 | 0.3202 | 0.1198 | 0.3202 |
An important property of all of these results is that the error for normal and tangent is the same. Because we are encoding a rotation, all axes of that rotation suffer equally under quantization. I’m going to make an empirical observation/argument that what we want here is a slightly asymmetric encoding: a lower error for normals may be desirable. Intuitively, changing the tangent direction affects the rotation of the extra normal map features whereas changing the normal direction affects lighting even if the normal map is flat; in addition, on densely tessellated meshes where normal quantization is more likely to produce visible artifacts, you’re less likely to have a meaningful normal map. Finally, if the normal map is not flat, the quality of the normals in the normal map is also subject to quantization artifacts; although BC5 could have up to ~11 bits per channel of effective precision depending on the block, so sometimes tangent encoding may still be a limiting factor.
I guess my point is: are you really going to notice if the tangent vector is rotated by a fraction of a degree? Let’s assume you won’t.
Tangent angle encoding
This is likely an older technique, but the earliest concrete reference I could find was in Rendering the Hellscape of DOOM Eternal, slide 35, and it proceeds as follows: let’s encode the normal as a unit vector, for which we already know to use octahedron encoding. Given a normal vector, we can construct an arbitrary orthogonal basis; tangent vector lies in the resulting plane and can be expressed as a single 2D rotation angle.
DOOM encodes all three components (two normal components and tangent angle) in a byte each; this is a little below our quality bar. But the important part here is that this allows us to vary the bit count we use for normal components independently from the tangent angle to hit our 32-bit limit.
Which basis should you use? It does not seem to matter that much. DOOM uses a pretty basic construction that’s a subset of Hughes-Möller; for an overview of older methods I recommend Perpendicular possibilities. The current state of the art seems to be Duff’s modification of Frisvad basis construction, described in Building an Orthonormal Basis, Revisited; it only has a single point of discontinuity and is pretty cheap to reconstruct.
What does seem to matter a lot is that during encoding you need to build a basis from the reconstructed normal. Because during decoding we will not have access to our original normal, and only have a reconstructed version from the quantized representation, it is critical that the angle that we store is computed in the basis that’s built from the same normal. If you use simpler basis construction, the reconstructed normal may fall into a different basis region and produce a completely different coordinate space (for example, if the basis changes when abs(Nx) > abs(Nz), it is possible that the original normal and the reconstructed normal disagree on which component is larger). If you use Duff/Frisvad construction, this is less likely, however there are areas of the sphere where the basis rotates quite violently, and this rotation will amplify the error if angle is encoded improperly.
Other than that, this method is straightforward; and we now have a few different bit allocation alternatives. Let’s look at a few examples:
| codec | bits | n_avg | n_max | t_avg | t_max |
|---|---|---|---|---|---|
| oct11x2+a10 | 32 | 0.0272 | 0.1136 | 0.0909 | 0.2065 |
| oct11x2+a9 | 31 | 0.0272 | 0.1136 | 0.1775 | 0.3588 |
| oct10x2+a11 | 31 | 0.0662 | 0.2256 | 0.0642 | 0.2256 |
| oct10x2s+a10 | 31 | 0.0444 | 0.1371 | 0.0954 | 0.2149 |
Note that in the first row, we are ignoring the problem of orientation bit storage: 11 bits * 2 components + 10 bits for the angle = 32 bits, which is our limit. However, in the next three variants we explore different versions to steal this bit back: steal it from the angle (worse tangent precision), steal it from the normal (which gives us an extra angle bit for free), and use aforementioned signed octahedron encoding which uses 10 bits * 2 components + 1 sign bit + 10 bits for the angle for the grand total of 31 bits, with one bit to spare for the orientation. In other words, the last three methods are complete and require no additional storage, whereas the first one is cheating a little bit to give a cleaner picture of the resulting errors.
While in all of these, the tangent error is a little (2-3x) worse than our original snorm10 baseline, it’s unlikely to matter in practice; and the other methods are fairly close to snorm10 in terms of normal error, and in fact the 11-bit octahedral encoding improves on it – again, despite using half the memory.
Out of these, my personal recommendation would probably be oct11x2+a9: it should have enough precision for the tangent angle in practice, and it allows us to store the orientation bit inline which results in a complete tangent storage you can simply plug in. To decode this, you need to do some trigonometry… it may be cheap or expensive depending on your GPU. Which brings us to the final option on the table.
Tangent diamond encoding
Described in Jeremy Ong’s post Tangent Spaces and Diamond Encoding, this is a very neat technique that can be seen as a version of tangent angle encoding, but whereas tangent angle requires sincos to reconstruct, here we project the direction onto a unit square in 2D space, and encode the direction in a manner similar to octahedron encoding. This gets us cheaper decoding at the expense of slightly uneven angular error.
Other than that everything relevant for tangent angle encoding applies here too: you need to select the orthogonal basis although the particular method to do it may not matter as much; and it’s critical that the basis is selected based on the reconstructed normal vector, which will be encoded using quantized octahedron encoding. Because we encode the diamond value separately, we have the same freedom of bit allocation.
That post argues that orientation bit could be stored at a higher-than-vertex granularity, e.g. per mesh/meshlet. While I handwaved the bit away in some encodings above, primarily because I was leading to the encodings that I actually like, I would probably not recommend this unless you work with very specific types of content where mirrored UVs just don’t show up. Having looked at hundreds of meshes in the last few weeks, you will encounter plenty of meshes with both UV orientations, you will encounter cases where orientation changes quickly in local proximity, and you may even encounter meshes where orientation diverges within a triangle, making per-meshlet orientation storage impossible!5 Just find a bit somewhere ;)
With that in mind, let’s look at the same options we’ve examined earlier; as a reminder, the first one needs 32 bits and doesn’t have space for the orientation bit (store it elsewhere!), whereas the last three reserve the orientation bit and reallocate the other bits between normal and diamond storage:
| codec | bits | n_avg | n_max | t_avg | t_max |
|---|---|---|---|---|---|
| oct11x2+d10 | 32 | 0.0272 | 0.1136 | 0.0864 | 0.2374 |
| oct11x2+d9 | 31 | 0.0272 | 0.1136 | 0.1691 | 0.4485 |
| oct10x2+d11 | 31 | 0.0662 | 0.2256 | 0.0614 | 0.2324 |
| oct10x2s+d10 | 31 | 0.0444 | 0.1371 | 0.0912 | 0.2431 |
Perhaps unsurprisingly, the normal errors are exactly the same as before: we are storing the normal in the exact same fashion! As far as the tangent error, the diamond storage holds up very well: the average errors are in fact a little smaller, whereas the maximum errors are a little larger. We would reasonably expect the maximum angular errors to be larger because the encoding is not uniform from the rotation perspective, but the extra error here is mostly quite reasonable. As before, if I had to pick one, I would pick oct11x2+d9, with oct10x2s+d10 as an alternative if tangent quality is critical.
Optimal rounding
One minor caveat that I omitted for simplicity but that you may want to incorporate into your actual encodings is optimal rounding. All examples above used basic per-axis rounding: when quantizing octahedron encoding, compute each component using floating-point math, and then convert it to SNORM representation with the correct number of bits, rounding to the nearest integer.
This is correct to do for independent axes; however, in many of the representations discussed, the axes are not independent because they represent a 3D vector or basis using a non-trivial transformation. As such, a more precise way to encode the exact same representation involves checking both rounding directions (floor/ceil) per component, and then picking the encoding with the minimum error. For two-component encodings like octahedron, this requires checking 4 combinations; for three-axis quaternions, this requires checking 8.
The gains you get are usually just in the worst case error and are incremental; I don’t feel like redoing the analysis for all the combinations but here’s an example for how it affects two encodings from the distinct groups we have examined:
| codec | bits | n_avg | n_max | t_avg | t_max |
|---|---|---|---|---|---|
| oct11x2+d9 | 31 | 0.0272 | 0.1136 | 0.1691 | 0.4485 |
| oct11x2+d9-opt | 31 | 0.0246 | 0.0816 | 0.1687 | 0.4485 |
| quat10x3+i2 | 32 | 0.0632 | 0.2046 | 0.0640 | 0.1988 |
| quat10x3+i2-opt | 32 | 0.0619 | 0.1480 | 0.0619 | 0.1507 |
For octahedron/diamond encoding, the tangent error doesn’t change because diamond encoding is single-axis so the only change is in how the normal is encoded; and while the improvement in the average error is modest, the maximum error drops a little further.
For quaternion encoding, as noted before, the precision equally affects all basis vectors; the average error is broadly unchanged but the maximum error shrinks noticeably too.
Overall it’s up to you whether to use the optimal encoding or not; it’s a little more code, but for offline processing it’s usually “free” - so getting a little extra quality boost may well be worthwhile. If you are using signed octahedron encoding, per-axis quantization is already close to optimal.
Conclusion
As I promised, this post does not contain original research :) because of this I’ve also avoided showing any specific shader code for decoding. If you’re interested in implementing any of this, please consult the excellent articles linked throughout the post for specifics! You need to be careful with encoding the angle/diamond based methods as I mentioned and reconstruct the basis from the decoded normal during encoding, but otherwise all of these should be easy and quick to try out.
Eyeballing the diamond encoding method, decoding a tangent frame encoded in this fashion needs ~50 ALU ops including bit manipulation if Duff/Frisvad tangent frame construction is used; this may seem high, but it’s probably still cheaper than using extra vertex data and there are ways to optimize this further: if you are using texture buffers (or Metal’s unpack_unorm10a2_to_float), then RGB10A2 decoding might be “free” in which case oct10x2s+d10 is a neat representation since it only requires you to separate the sign for signed octahedron decoding from the tangent orientation, and could be 20% cheaper or so overall.
If this does still seem high, you would need to measure the resulting decoding cost and decide. Quaternion representations should be a bit cheaper to decode, but inability to redistribute the encoded bit count and inability to fit the extra bit into the 3x10+2 bit encoding is certainly not ideal.
But if you are still using 8-byte or larger tangent frames, consider that DOOM Eternal uses just three bytes6, repent, and quantize away!
For convenience, here’s the average error plot as well as a full table with all experiments above, although do note that some of these use the full 32 bits without space for the orientation bit, for which you would need to find space elsewhere in the vertex.
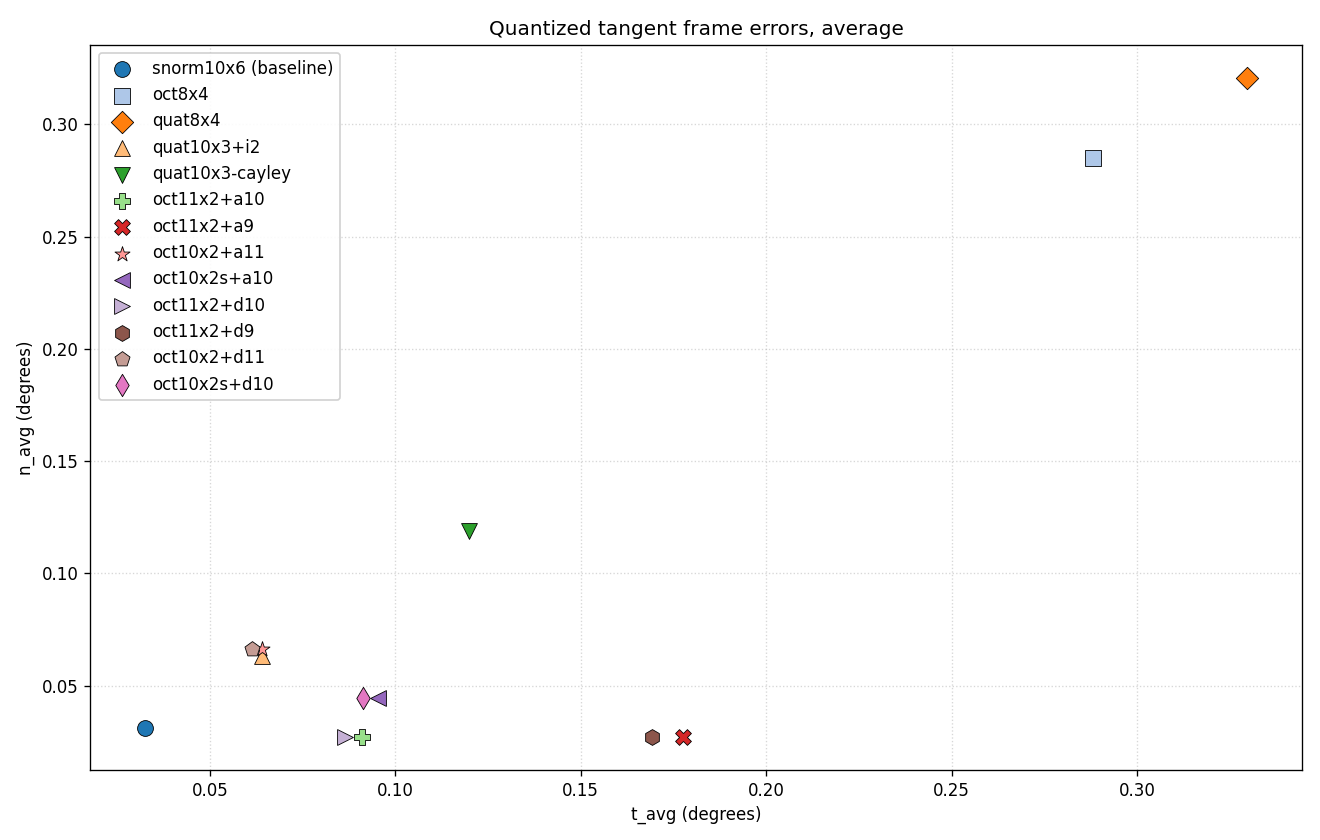
| codec | bits | n_avg | n_max | t_avg | t_max |
|---|---|---|---|---|---|
| snorm10x6 (baseline) | 60 | 0.0310 | 0.0949 | 0.0326 | 0.0907 |
| oct8x4 | 32 | 0.2849 | 0.9113 | 0.2882 | 0.9117 |
| quat8x4 | 32 | 0.3208 | 0.8738 | 0.3296 | 0.9022 |
| quat10x3+i2 | 32 | 0.0632 | 0.2046 | 0.0640 | 0.1988 |
| quat10x3-cayley | 30 | 0.1191 | 0.3202 | 0.1198 | 0.3202 |
| oct11x2+a10 | 32 | 0.0272 | 0.1136 | 0.0909 | 0.2065 |
| oct11x2+a9 | 31 | 0.0272 | 0.1136 | 0.1775 | 0.3588 |
| oct10x2+a11 | 31 | 0.0662 | 0.2256 | 0.0642 | 0.2256 |
| oct10x2s+a10 | 31 | 0.0444 | 0.1371 | 0.0954 | 0.2149 |
| oct11x2+d10 | 32 | 0.0272 | 0.1136 | 0.0864 | 0.2374 |
| oct11x2+d9 | 31 | 0.0272 | 0.1136 | 0.1691 | 0.4485 |
| oct10x2+d11 | 31 | 0.0662 | 0.2256 | 0.0614 | 0.2324 |
| oct10x2s+d10 | 31 | 0.0444 | 0.1371 | 0.0912 | 0.2431 |
Addendum
After the article was published, a few people had observations that were not present in the original version of the article, but are worth sharing here:
Andrew Helmer pointed out that another possibility is to use a Fibonacci lattice (paper, Shadertoy), which can encode a unit vector into a single integer. Decoding requires sincos in addition to a few other ops and looks more expensive than octahedron decoding; the precision is pretty close if you are using an even-numbered bit count, and a little better for odd-numbered bit count when the alternative is signed octahedron encoding. I am not including this in the results above, but curious minds can investigate this further.
Mateusz Kielan pointed out two interesting considerations that have to do with visibility buffers. First, visibility buffer rendering involves decoding triangle data per pixel and interpolating the results; this increases the cost of decoding any compressed representations as it needs to be done three times per pixel, which may offset the tradeoffs. Second, with quaternions specifically, this presents a convenient opportunity to interpolate the quaternions instead of interpolating the reconstructed basis vectors. Interpolating quaternions linearly requires handling dot(q1, q2) < 0, but since the shader has access to all three, it’s easy to do; nlerp is generally sufficient from the quality perspective here. Note that to apply the same optimization in a non-visibility-buffer pipeline, you have to either use barycentric extensions to do the interpolation manually, or pre-flip quaternions in individual vertices such that in each triangle any two corners have aligned quaternions. GPU Pro 5 chapter Quaternions Revisited covers this in more detail.
Tom Forsyth pointed out that if you do want to preserve non-orthogonal tangent frames, as long as the basis vectors are unit-length and orthogonal to the normal, you can still use some of the techniques mentioned in this article to save space. Notably, you can use diamond encoding to encode both tangent and bitangent vectors - 32 bits is no longer going to suffice, but you can use something like oct12x2+d12+b12 to encode the normal using octahedral encoding and encode tangent and bitangent using a scalar for each. This results in 48 bits (the orientation bit is not necessary as the bitangent is encoded explicitly and isn’t reconstructed) with excellent precision, and you can always reduce the bit counts, including asymmetric variants (e.g. oct11x2+d9+b9 = 40 bits), if the budgets are tight and use the remaining bits for something else in your vertex.
-
If you have been referring to these as binormals then I would respectfully ask you to reconsider. ↩
-
Since I know too much about MikkTSpace now - for UV-degenerate triangles MikkTSpace will use tangent vector
(1 0 0)which is not necessarily orthogonal to the normal as a fallback; but forcing orthogonalization in these cases is unlikely to hurt, and this is a topic of a separate discussion. ↩ -
Unit-length vectors are technically also a simplification; but again one that is commonly accepted. In some cases it can be useful to be able to represent zero-length tangent vectors; this can be incorporated via an extra bit or a sentinel value in some of the encodings described. MikkTSpace can also occasionally generate zero-length tangents although this is quite rare. ↩
-
This requires slightly tweaking
wwhen it’s exactly equal to 0, and requires a bit of extra care if quantization is used. ↩ -
Okay, this is a MikkTSpace special that is perhaps not hugely relevant here because it only shows up on UV-degenerate triangles where one or two corners have fallback tangents anyway, and these frames are not orthogonal. Still, you should probably switch to meshoptimizer’s tangent space generation where this problem is fixed ;) ↩
-
In fairness, the 3-byte representation seems specific to vertex animated meshes, where you probably don’t notice the artifacts at all :) ↩
| « meshoptimizer 1.0 released | Zigzag decoding with AVX-512 » |